
����1��������2����С�� 1������1�����뻪2
��1.����������ѧ ������Դ����ѧԺ������ ���� 650093��
2. ���Ҳ�������Ϣ���Ĵ�����������Ϣ���ģ��Ĵ� �ɶ� 610041����
ժҪ��������Ե������������ȡWeb�ռ�������ץȡ�����ʺ�ץȡЧ���Ͼ��ܵ�һ���̶ȵ����ƣ����Ա�֤��ץȡ���ݵļ�ʱ���Լ�ȫ�������⣬�о��˻��ڷֲ�ʽ���������Web�ռ����ݻ�ȡ����������˻��ڷֲ�ʽ���������Web�ռ����ݻ�ȡԭ��ϵͳ��������ʵ�֣�����ͨ����ԭ��ϵͳ������صIJ�����֤ʵ�˱�������������������Ч�ԡ�
�ؼ�����Web�ռ����ݣ��ֲ�ʽ�������棻ԭ��ϵͳ
����ͼ����š�P208 �����ױ�ʶ�롿A
Research on web spatial data acquisition based on distributed web crawler
FENG ling1,ZENG Liyang2 ,UO Xiaoqing1,HUANG liang1,ZHU Qihua2
��1. College of Land Resources Engineering , Kunming University of Science and Technology , Kunming 650093 , China;2. National geographic information bureau Sichuan basic geographic information Center, Chengdu 610041 ,China��
Abstract��The acquisition of web spatial data by single network crawler is limited in the crawl coverage and crawl efficiency so it is difficult to ensure the timeliness and comprehensiveness of data acquisition. In this paper, based on distributed web crawlers, the method of web spatial data acquiring is studied; a prototype system of web spatial data acquisition is designed and implemented and the proposed method in this paper is validated to be effective by testing the prototype system.
Key words��Web spatial data��Distributed web crawler��The prototype system
0����
GIS��һ��������Ϊ������ѧ�ƣ��ռ�������ռ�ͳ�ƺͿռ������ھ���о����벻���ռ����ݵ�֧�ţ����������д��ں����ռ����ݣ���Щ���������ǵ��ճ�����������ز��Ұ�������Ϣ��ʮ�ַḻ�������Լ�ǿ������ܹ��Ի������й㷺���ڵĿռ����ݸ�Ч�ؽ��л�ȡ��һ������Բ������������Ϣ�IJ��㣬�ṩ�ḻ��ϸ�ں�ʵʱ���£���һ���滹�ܹ�ΪGIS�ռ�����Ϳռ������ھ��ṩ��Ϣ���ḻ����ʱЧ�Ե�����Դ��
Web�ռ����ݻ�ȡ��Ҫ�����������漼��������������ѧ�����ⷽ��������о���Leasure D Rָ���������������漼�������ԷḻGIS�ռ������������Դ[1]�� Tezuka T���о�������������漼��������Web�ռ����ݻ�ȡ���Ѷ�[2]��Zhang C J����˻����������漼���ĵ�����ַ����·���[3]��Hua-Ping Zhang���о��˴ӻ��������ű������Զ���ȡPOI���ݵķ���[4]��Li W�о��˻������������OGC�����ַ���[5]��Chen X������������ʵ�����Զ������ֺͼ���WMS����[6]��Jiang J�о��˼���WFS�������������[7]������������ͨ�������漼������������˿ռ����������˼����ϵ�����Ӷ�������������˲���[8]���̵����о���Դ���������ܵĻ����ϣ����ͨ�����̺߳��첽I/O���ֲ������Ż�Web�ռ����ݵĻ�ȡЧ��[9]��Ager A�����о���ָ��������ܹ���Web�ռ����ݽ�����Ч�����ã�����GIS�ķ�չ������Զ��Ӱ��[10]��
ͨ�������������о���״���֣�Ŀǰ�������������Web�ռ����ݻ�ȡ�о���������õ��������������ʽ��Ȼ����Web�ռ����ݹ㷺�ֲ��ڲ�ͬ������վ�����Ҹ���Ƶ�ʿ죬����������������ץȡ������ץȡ�����ʺ�Ч�������������������Ա�֤ץȡ���ݵļ�ʱ�Ժ�ȫ���ԣ���˱�����Ե������������ȡWeb�ռ����ݴ��ڵ����⣬�о����ڷֲ�ʽ�����������Web�ռ����ݻ�ȡЧ�ʡ�
1�ֲ�ʽ��������ʵ��ԭ��
���ڷֲ�ʽ���������Web�ռ����ݻ�ȡ��������ͨ�����ӵ�������ϵͳ�ĸ��ɶ���ͨ�����Ӹ��������ϵͳ��Ա��������ݻ�ȡ���ܺ�Ч�ʣ������ö�̨����һ��Ļ�����������ץȡ��ͬʱ��ÿ̨�����ϲ��������棬��������ץȡ�IJ����ԡ������ʵ�ַ�ʽ�Dz��ò�ͬ�Ļ����е���ͬ�Ľ�ɫ�ֹ���ѡȡһ̨���ܽϺõĻ���ר�Ÿ���URL��Uniform Resoure Locator��ͳһ��Դ��λ������ͳһ���Ⱥ�ȥ�أ�����̨������Ϊ���ڵ㣬��Ҫ����������ά������ȡURL���к�����ȡURL���С����ö�̨����һ��Ļ�������ʵ�ʵ���ҳ���غ����ݽ���������Щ������Ϊ����ڵ㡣
����������ֲ�ʽ�������������ԭ����ͼ1��ʾ������ڵ�����ڵ�����URL��������ץȡ����ץȡ���ݵ�ͬʱ�����µ�URL��������URL���������ڵ㣬���ڵ㸺�������ڵ��ύ��URL����ȥ�أ�������������ȡURL���С�����ڵ�֮��û��ͨ����ϵ��ÿ������ڵ�ֻ�����ڵ����ͨ�ţ����ڵ�ͨ��һ����ַ�б�������ϵͳ����������ڵ����Ϣ����ˣ����ֲ�ʽ��������ϵͳ�еĽڵ��б仯��ʱ����������ڵ㣬ɾ��ij����ڵ㣬������ڵ��ַ�����仯�������ڵ�ֻ�������ַ�б������ݣ�����ڵ�ֻ��Ҫ����ץȡ���ݡ�ͬʱ�����ڵ㸺��Էֲ�ʽ��������ϵͳ�и�����ڵ���и��ؾ��⡣

ͼ1�ֲ�ʽ��������ʵ��ԭ��ͼ
2ϵͳ�����ʵ��
2. 1ϵͳ�ܹ�
ԭ��ϵͳ�Ǹ��������ֲ�ʽ��������ʵ��˼·�������ڵ��ϲ���Redis�������ݿ���������ά���ֲ�ʽ��������ϵͳ�и�����ڵ㹲��������ȡURL���кʹ���ȡURL���У�����ڵ�֮��û��ͨ����ϵ��ÿ������ڵ㶼�������ڵ�Redis����������������ӣ�����ÿ������ڵ��ϲ���MongoDB���ݿ⣬�����洢����ץȡ�������ݡ��ֲ�ʽ��������ϵͳ�е�������ڵ��ϵͳ�ܹ���ͼ2��ʾ��

ͼ2 ����ڵ�ϵͳ�ܹ�
2.2 ϵͳʵ��
����ͨ���Կ�Դ����������Scrapy������ȿ�����ʵ������Web�ռ����ݻ�ȡ�ķֲ�ʽ��������ԭ��ϵͳ��Scrapy��һ��Ϊ����ȡ��վ���ݣ���ȡ�ṹ�����ݶ���д�Ļ���python���Ե�Ӧ�ÿ��[13]��������Twisted�첽���������������ͨѶ[14]�������߿��Զ�Scrapy��ܽ�����չ�������������Ķ��ƣ�����ʵ���˶��Ƶĵ������������������ݹ��������������м������������������������ʹ��Scrapy����Դ���ģ�顣��1Ϊԭ��ϵͳ�Ŀ���������
��1 ԭ��ϵͳ��������
|
�������� |
Python2.7.11 |
|
|
|
|
Ӳ��������ϵͳ |
64λWindows8ϵͳ��4G�ڴ桢i7-3612QM������
|
|
���ݿ� |
MongoDB 3.2.0��Redis 3.0.501 |
|
�������� |
Eclipse+PyDev |
|
MongoDB���ݿ�������� |
Robomongo 0.9.0-RC7 |
|
Redis���ݿ�������� |
RedisStudio-en-0.1.5 |
3ϵͳ������������
3.1���Ի���
����ʹ����̨������ͨ��PC��������ϵͳ���ԣ�ѡ�������ڴ�ϴ��һ̨����Ϊ���ڵ㣬�����ϰ�װRedis�������ݿ�����ά������ȡURL���к�����ȡURL���С�ʹ��������̨PC������ʵ�ʵ���ҳ���غ����ݽ����������ϰ�װpython������MongoDB���ݿ⣬������Ϊ����ڵ㣬����ʱ���������Ϊ8Mb/s��
3.2���Խ������
Ϊ�˱�������������ʵ����Բ���Ӱ�죬��ϵͳ����ʱ�䶨������10��������7�㣬ϵͳ������9��Сʱ���ֱ�������������ֲ�ʽ��������ϵͳ���������ԣ����������IJ��Խ�����2��ʾ��
��2����������Խ��
|
����ʱ�䣨Сʱ�� |
ץȡ�������������� |
|
1 |
6183 |
|
2 |
12090 |
|
3 |
18358 |
|
4 |
24339 |
|
5 |
30559 |
|
6 |
36860 |
|
7 |
43124 |
|
8 |
49193 |
|
9 |
55453 |
�ֲ�ʽ���������IJ��Խ�����3��ʾ��
��3 �ֲ�ʽ����������Խ��
|
����ʱ�䣨Сʱ�� |
ץȡ�������������� |
|
����ڵ�1 |
����ڵ�2 |
����ڵ�3 |
�ܼ� |
|
1 |
6024 |
6015 |
6351 |
18390 |
|
2 |
11423 |
11331 |
12029 |
34783 |
|
3 |
16287 |
16594 |
18340 |
51221 |
|
4 |
22716 |
22135 |
24041 |
68352 |
|
5 |
27931 |
27388 |
29856 |
85175 |
|
6 |
34129 |
32639 |
35826 |
102594 |
|
7 |
39829 |
37915 |
41575 |
119319 |
|
8 |
45796 |
42584 |
47392 |
135772 |
|
9 |
51585 |
47916 |
53332 |
152883 |
��ʵ�����ݽ�����Ƴ�����ͼ��ʵ������ͼ3��ʾ��


ͼ3 �ֲ�ʽ����������Խ��ͼ
��ͼ3��֪���ֲ�ʽ��������ϵͳ����������ڵ�ץȡ���ݵ�����������ʱ��ɽ�����Ϊ��������ϵ����˵��ԭ��ϵͳ�ܹ��ȶ������С�������ͼ�ĺ���������Եó���ÿ���ߵ�б�ʾ���������ȡЧ�ʣ������ֲ�ʽ��������ץȡ������Ч��Զ����������������˵���������ʵ�ֵķֲ�ʽ��������ϵͳ�������õ���չ�ԡ����Թ����У�ÿ������ڵ�ץȡ���ݵ������ͼ4��ʾ��

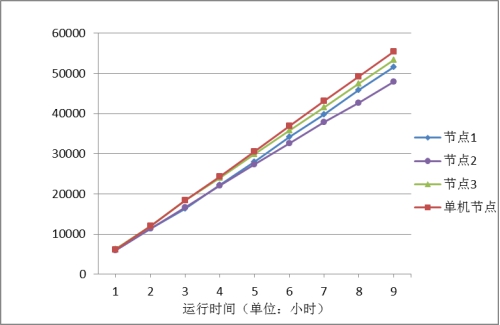
ͼ4 �����벢�нڵ����ܶԱ�ͼ
��ͼ4��֪���������ֲ�ʽ��������ϵͳ������ȡʱ������������ÿ���ڵ����ȡЧ��ͬ����������������½�����������½�����������Χ֮�ڣ���Ϊ����ڵ�ͬʱ����ʱ����ͬһ����������ӿڣ�����������˲������е���Ҫƿ����ͬʱ��ͼ4�л����Ե�֪���ڵ�һ���ڵ�����ڵ��������е�����ȡ��������������ͬ����˵��������ƺ�ʵ�ֵķֲ�ʽ��������ϵͳ�ܹ�ʵ��ϵͳ�����ڵ�֮�为�ؾ��⡣
4������
������Ե������������ȡWeb�ռ�������ץȡ�����ʺ�ץȡЧ�����ܵ����ƣ����Ա�֤ץȡ���ݵļ�ʱ�Ժ�ȫ���Ե����⣬�о��˻��ڷֲ�ʽ���������Web�ռ����ݻ�ȡ������ͨ��ʵ������Ա�֤����������������ڷֲ�ʽ���������Web�ռ����ݻ�ȡ���� �ܹ����Web�ռ����ݻ�ȡЧ������ƺ�ʵ�ֵ�Web�ռ����ݻ�ȡԭ��ϵͳ�ܹ��ȶ����У�����ϵͳ�������õ���չ�ԣ�ϵͳ�����ڵ�֮���ܹ�ʵ�ָ��ؾ��⡣
�����:
[1] Leasure D R. Geodata Crawler��A centralized national geodatabase and automated multi-scale data crawler to overcome GIS bottlenecks in data analysis workflows[J].
[2] Tezuka T��Kurashima T��Tanaka K. Toward tighter integration of web search with a Geographic information system[C].Proceedings of the 15th international conference on World Wide Web. ACM��2006��277-286.
[3] Zhang C J��Zhang X Y��ZhuS N��et al. Method of Toponym Database Updating Based on Web Crawler[J]. J.Geo-Inf. SCI��2011��13��492-499.
[4] Hua-Ping Zhang��Qian Mo.Structured POI data Extraction from Internet News[C].The 4th International Universal Communication Symposium (IUCS)��Beijing��2010.
[5] Li W��Yang C. An active crawler for discovering geospatial web services and their distribution pattern-a case of study of OGC web map service [J].International Journal Geographical Information Science��2010��24(8)��1127-1147.
[6] CHEN X��CHEN R��WEI W. Design and Realization of Web Service Snatch and Parse Engine Based on Web Crawler [J].Geomatics World��2010��3��016.
[7] Jiang J��Yang C��Ren Y .A spatial information crawler for opengis wfs [C].The 6th International Conference on Advanced Optical Materials and Devices. International Society for Optics and Photonics��2008��71432C-9.
[8] ������.����Web�Ŀռ�������ȡ������о�[D].�人��ѧ��2013.��
[9] �̵�.��������Դʸ���ռ������Զ���ȡ����������о�[D].�й�����ѧ�о�Ժ��2015.
[10] Ager A��Schrader-Patton C��Bunzel K��et al. Internet Map Services��New portal for global ecological monitoring��or geodata junkyard?[C].Proceedings of the 1st International Conference and Exhibition on Computing for Geospatial Research &Application.ACM��2010��37.
[11] Ryan Mitchell. Web Scraping with Python[M].Sebastopol��O��Reilly Media��Inc�� 2015.7-24.
[12] Scrapy developers. Scrapy Documentation Release 1.0.3. 2015.8-15.
[13] ������.����Twisted�ܹ���GPSЭ��ת�������ص������ʵ��[D].�㽭��ҵ��ѧ��2013.



